

I think that before talking about transaction isolation levels it’s fair to start with a term transaction itself. According to SQL specification (ISO/IEC 9075-1) it’s:
A sequence of executions of SQL-statements that is atomic with respect to recovery. That is to say: either the execution result is completely successful, or it has no effect on any SQL-schemas or SQL-data.
That said, transaction isolation levels could be, perhaps, defined as modes that determine an extent to which logically parallel transactions can affect each other, or step on each others heels so as to say. Usually they come up on an interview or when trying to answer such questions as:
- What problems - so called "side effects" - can arise when transactions are logically ran in parallel?
- How do we avoid side effects to ensure maximum data integrity, while doing our best to keep performance optimal?
Side Effects
To answer the first question let’s talk about side effects a bit more to understand what they are and what kinds of problems they represent. First of all, side effects have “complexity” levels assigned to each of them, in terms of how difficult it is to spot them, fix them and prevent them. From the most simple to most complex, following side effects can be listed:
Lost Update < Dirty Read < Non-Repeatable Read < Phantom Read
Lost Update
Is a situation when several transactions update the same data almost simultaneously, without taking each other’s updates into consideration. The end result is not pretty - like only some of those transactions actually did the job and results of others are lost. For better understanding, I would draw a parallel with the “data race condition” - a familiar term every programmer out there have heard at least once.
Dirty Read
Is a situation when transaction can read a data that was just added or updated in a different (parallel) transaction even though COMMIT has yet to be made. There is also a situation when transaction fails to see some data, because it was just removed in a parallel transaction, once again without COMMIT.
This side effect is pretty dangerous. To understand that, just imagine a situation when transaction A reads some data and updates it without commiting (yet). If a parallel transaction B can already access updated version and work with it, and A fall-backs for some reason, then B will just continue doing its job and would possibly write the end result to DB, even though it’s calculated based on uncommitted data.
Non-Repeatable Read
Is a situation when a repeated read request produced different result even though it was executed in the same transaction. Just to make it clear, here we talk about data that was retrieved once - e.g. 10 rows a table discounts. Imagine that for some reason we need to retrieve them again with the same query and in the same transaction. We don’t expect those rows to have different values, but depending on isolation level used, that may be exactly the case, if another transaction updated the data between the first and the second query. Depending on what we consider expected behaviour, this could be a problem.
Phantom Read
Is a situation similar to Non-Repeatable Read. The difference is that read request executed in a same transaction returns different amount of data (rows). E.g. if the first one returned 10 rows and the second one 15 - there we have it. Same as previous one, in some systems this can be considered expected behaviour and in others this could present a nasty surprise we probably don’t want to deal with.
Isolation Levels
Now that we’ve talked a bit about side-effects, let’s move to transaction isolation levels that help us to deal with them. We’ll go over each one of them, but for now here is a table showing what side effect can potentially happen if specific mode is used, just as a reference.
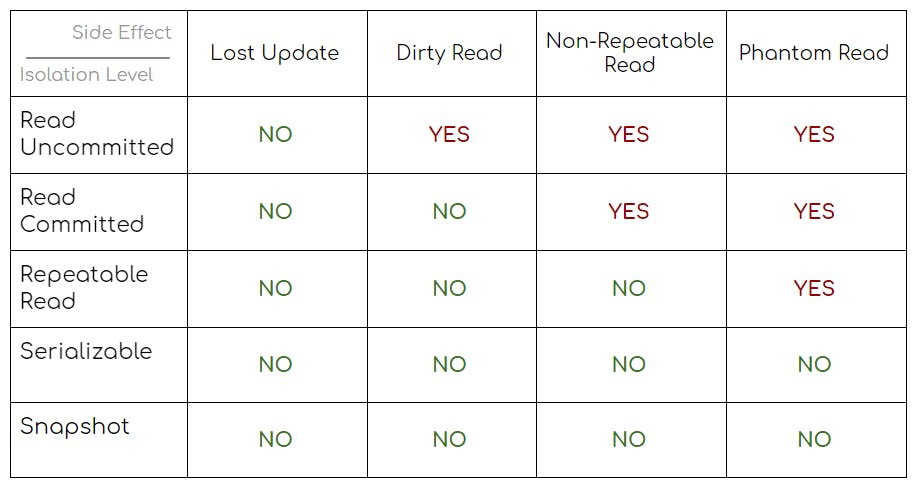
Those side effects you can see in the table are actually described in SQL specification and guarantee that - depending on a chosen isolation level - some side effect won’t be able to mess up integrity of our data. As it have been mentioned earlier, side effects have complexity levels assigned to each of them. We just have to remember that if specific mode doesn’t guarantee the absence of some specific side effect, then all side effect that have a higher complexity level might as well happen. Now the question is: What side effects we can avoid using each specific transaction isolation level?
First of all the absence of lost updates is guaranteed by any mode. And it’s essentially the only side effect that is prevented by Read Uncommitted. As you can probably guess, reading of uncommitted data is entirely possible, as well as more complex side effects. Because of that, this mode is rarely used in practice nowadays.
More commonly used level is Read Committed, which allows to avoid dirty reads by locking data we’re trying to read. As long as transaction is in the middle of writing some data, other (logically parallel) transactions won’t be able to read the data that is being written until it’s committed. More complex side effects might still happen though.
To further solve the problem we have Repeatable Read. This mode prevents non-repeatable reads by locking data that is being written till the end of transaction - unlike previous transaction isolation level that does the same lock only for duration of write. Now the only thing that can make our life miserable is phantom read.
To save the day once and for all we can use Serializable. It works by locking data for writes and reads of any block we are interested in. Even insert is locked if it's targeting a block that has been already read earlier. This mode ensures maximum data integrity, but since it’s pretty “pessimistic” - has long and full locks - it has relatively low performance in comparison with alternatives.
An alternative defence against all side-effects is Snapshot. Unlike all modes described earlier this one doesn’t use locking mechanism at all - versioning principles are used instead, somewhat similar to VCS such as Git and Mercurial. Essentially every transaction has its own snapshot of data that is completely isolated from other transactions and thus can’t be affected by them. The main problem here is a possible situation when two commits have a conflict. In this case we have to resolve it somehow.